lightdm, the desktop manager running on ther server, is in a failed status- The
ModemManagersystemd service is not present - The
NetworkManagersystemd service is not present
How to crash a ground station
Published: 2022-07
During my master's studies I have been collaborating with the WARR MOVE student association. They allow students to develop research satellites, improving their technical and social skills while working in an environment similar to the one found in the aereospace industry. My main task has been to develop and maintain a good chunk of the software that runs on the MOVE's ground station, which is used daily by our mission controllers to communicate with the two satellites that are currently in orbit: MOVE-II and its twin MOVE-IIb.
As part of the quality control process for deploying a new version of the ground station system, we executed a limited test involving only some upgraded components. This test was designed to be as minimal and non-invasive as possible, ideally resulting in only minimal service disruption. Of course, in the best of traditions, it ended up causing the first outage of the system in the last few months. 🤦
The test was going smoothly until, suddenly, just before the satellite started its overpass over the ground station, the ground station server stopped responding. All the already opened SSH connections froze, and it was not possible to open new ones. We had no choice but to interrupt the test and try to figure out what went wrong.
After reaching the roof of the university (because of course the first time I manage to lock myself out of a server it has to be on a roof) and looking at the server's physical console we found it happily running. No crash at all. I found the system exactly in the same situation as I left it. It had even executed the last command I issued just before it became unreachable. Weird.
I tried reconnecting via SSH, but to no avail. As the server runs a relatively recent
Debian, my first thought was that the problem involved the
sshd service, which is
responsible for managing SSH connections to that machine. I tried to restart it:
$ sudo systemctl restart sshd
Although the service restart was successful, as attested
by systemctl status sshd,
the groundstation server was still unreachable, so it was not a transient error.
Unfortunately, my time on the roof was limited. Therefore, I rebooted the whole server. After the reboot, I tested again the SSH connection, and it worked. Moreover, I quickly checked that all the ground station systems were back online, and they were. The outage was fixed, normal operation could resume, and I could start breathing again.
However, I still wanted to investigate the root cause of this problem: solving an issue with a reboot is only calling for more reboots in the future. Luckly, before the reboot I took a snapshot of the status of the various services that where running at that moment on the groundstation with:
$ sudo systemctl list-units --type=serviceAfter the reboot, I re-issued that command, and compared the output before and after. The interesting differences are shown here below, the left part is before the reboot, the right part is after:
UNIT LOAD ACTIVE SUB
[...]
lightdm.service loaded failed failed
loadcpufreq.service loaded active exited
mosquitto.service loaded active running
networking.service loaded active exited
[...]
UNIT LOAD ACTIVE SUB
[...]
lightdm.service loaded active running
loadcpufreq.service loaded active exited
ModemManager.service loaded active running
mosquitto.service loaded active running
networking.service loaded active exited
NetworkManager.service loaded active running
[...]
As you can see, there are three main differences. Before the reboot:
In order to investigate these failed services I checked the system logs that were generated just before the reboot:
$ sudo journalctlThis is what I found (with the sensitive parts redacted):
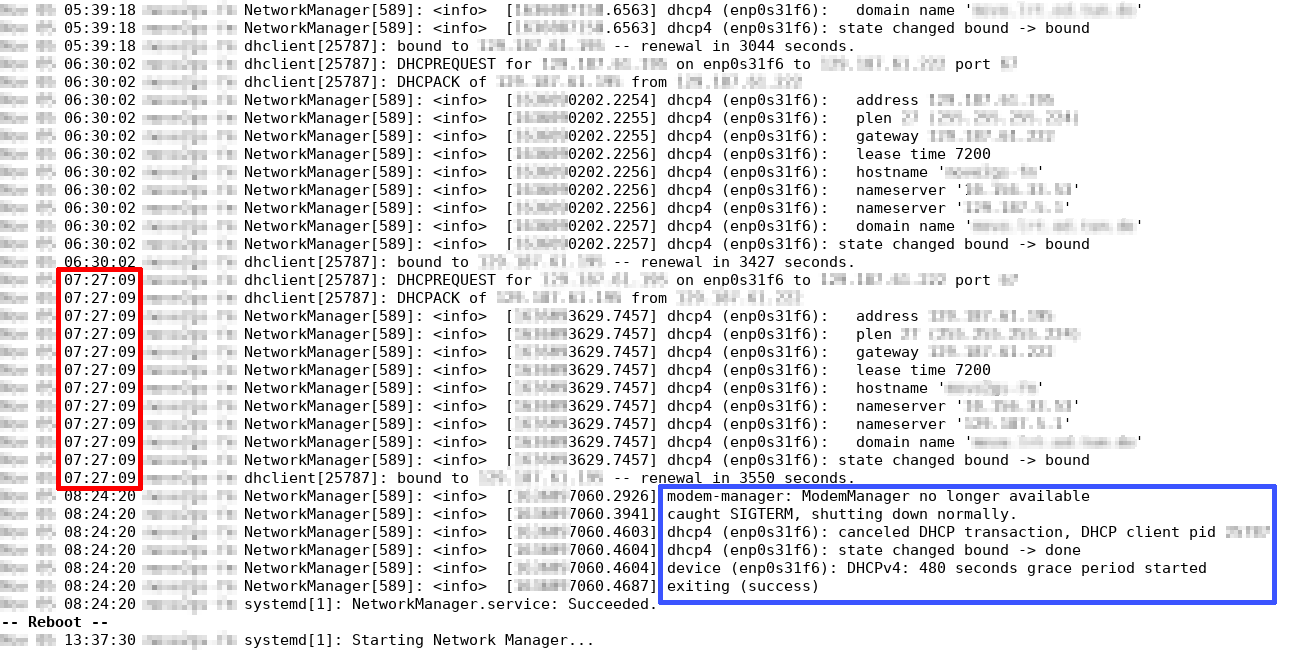
Here it can be seen that most of the log messages before the reboot are indeed generated by
NetworkManager. At 7:27 it renews the
DHCP
lease for the ground station server and then it... exits at 8:24?! NetworkManager isn't supposed to just exit, it is required to (among
other things) regularly renew the DHCP lease. More precisely, it detected that ModemManager was no longer available and then received a SIGTERM, which in Unix systems is a way to politely ask a process to shut itself off. Of course, NetworkManager happily complied with the request.
Without NetworkManager renewing
the DHCP lease, it was eventually bound to expire. From the logs, we see that
the ground station server is configured to have a lease time of
7200 seconds (exactly 2 hours). This means
that, if the last lease renew was at 7:27, we would expect the current lease to
expire at 9:27. That is exactly around the time window which was scheduled for the
test, as the satellite overpass began at 9:32.
This means that the outage that was experienced during the test only affected the network connectivity of the ground station server and was due to a DHCP lease not being renewed on time. Mistery solved.
However, a question remains. Why was ModemManager
not available? Back to the logs!
$ sudo journalctl -u ModemManager
Here we can see the logs for ModemManager before
the reboot:

We can see that at 8:24, the same time at which
NetworkManager
exited, ModemManager
could not acquire the
org.freedesktop.ModemManager1
service name and then exited. I am not an expert with DBus, but after asking
Google it seems that
org.freedesktop.ModemManager1
is the name with which
ModemManager registers
itself to DBus.
DBus is a system bus that usually is available un Linux systems. It allows different processes to easily communicate with each other.
I am not entirely sure on why ModemManager
was not able to acquire its own name, but, when thinking about it, I remembered
that during the preparation for the test I did interact with DBus in some way.
I was troubleshooting an issue with the code that was going to be tested, and as
part of it I absent-mindedly restarted the system DBus instance with
sudo systemctl restart dbus.
My reasoning was that normally, in distributed systems, clients are designed to be resilient to a transient failure of other clients and of the communication bus, if one is used. The commonly used strategy vary and range from simply retrying to connect if an error is received to more complex solutions like the circuit breaker pattern. Therefore, in my mind, restarting DBus was a perfectly safe operation.
A quick Google search revealed however that this is not the case: most applications do not
expect the system bus to restart, and therefore do not try to reconnect to it if an error
happens. When I restarted DBus, the connection that many services had to it was destroyed.
This caused an error at 8:24, when ModemManager then tried to communicate with the system bus, resulting in ModemManager shutting down.
Further evidence that this is exactly what happended can be found in the logs from lightdm, the service that was in the failed
status before the reboot:
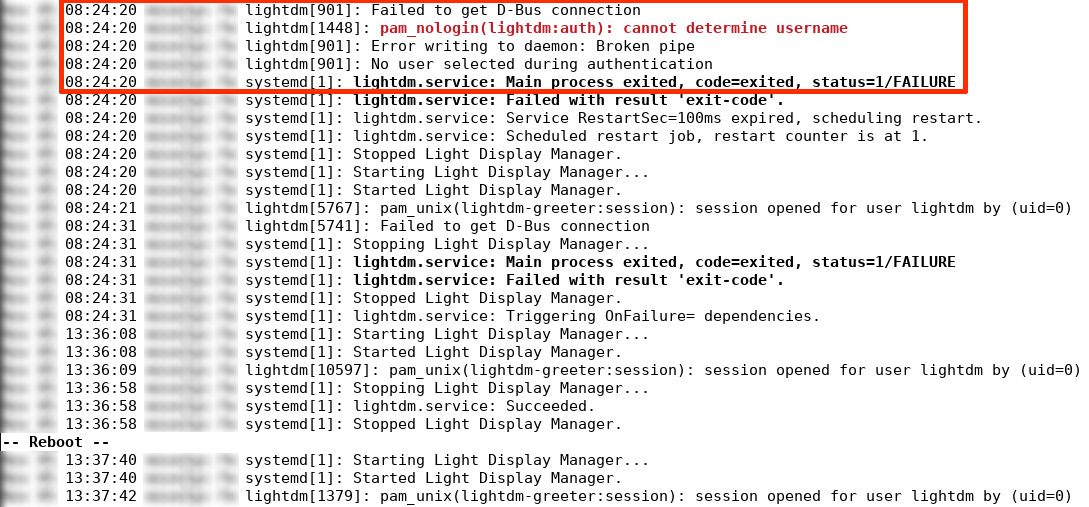
The final confirmation that this was actually the root cause of the issue can be obtained by restarting DBus on a healty system: after doing that I obtained exactly the same log messages, indicating that indeed the root cause for the outage was the DBus restart. This also explains why a system reboot was a sufficient fix for the issue, as it forced all the services to reacquire a new connection to the system bus.
This was a fun (🥲) issue to debug, and I hope that writing this down will save other people from making the same mistake. My only wish is that the next time something like this happens, the server in question will not be again on a roof.